


Sector access interruption of Seagate drives is a hard nut to crack in data recovery industry with a high probability of occurrence, but if we want to repair it, it will be time-consuming and the success rate is low.
Compared to other malfunctions of Seagate drives, it is very easy to determine and identify “sector access interruption” problem. The symptoms are that when scanning, we can normally read out the data from sector 0 to a specific sector, but from that specific sector to the end, all the sectors are unable to get the data with errors of ERR and UNC (Ie, the ERR light of device status and UNC light of error status will light up). We can confirm the problem is “sector access interruption” if one Seagate drive is with above two symptoms.
Basically, Seagate repair tools in the market are able to solve some “sector access interruption” cases, but those tools can not solve all of them. Why? This is because “sector access interruption” can be divided into four different types, and different type needs different solution. So this document will have a depth analysis of Seagate sector access interruption, aiming to help users to locate the real problem the very first time and use the best solution to work it out.
In fact, the root cause of “Seagate sector access interruption” is translator disorder. And now let’s discuss the possible reasons of translator disorder.
We know that the translator is actually an address convertor. When computer reads data from hard disk, it will tell the disk the needed content with a specific LBA address, so that the disk will return the data of that corresponding address. However, address description form of underlying firmware needs to be positioned to C (Cylinder), H (Head) and S (Sector), and in the process of translation, some bad sectors can be shielded, so that the logical address will looks like a continuous linear address while corresponding physical address is with projective mapping jumps. As shown in the picture:
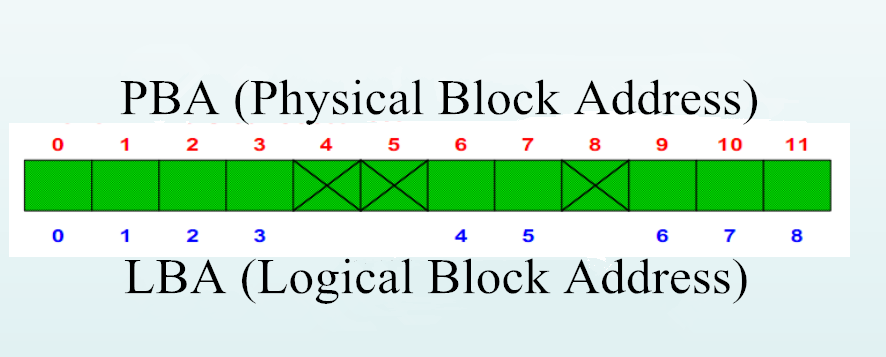
In short, that is, if there is no any shielded sector, PBA=LBA; if there are shielded sectors, PBA=LBA+ the length of all shielded sectors.
The situation of “PBA=LBA” is an ideal state, because bad sectors will come into being from the beginning of hard drive’s production. Generally, hard drive’s sectors can be divided into firmware area, work area and reserved area. Firmware area and reserved area are not accessible to users, so we can not directly operate them. In fact, the number of actual sectors is larger than the number we can see from disk label. Among those sectors, a part of them are used to store firmwares, a part of them belong to work area and are used to store user data (the capacity of them equals with the one in disk label), and the rest are reserved area. However, hard disk wont reserve some sectors for reserved area veritably, it is only because the available sectors are more than the defined sectors, so the exceeded sectors will be regarded as reserved sectors.
We’ve discussed the structure of all sectors just now, and here we will pay attention to the structure of a single sector. There are two main parts of one complete single sector: location identifier of stored data and segment of stored data. As shown in the picture:

The first major part of one sector is the identifier. Identifier refers to sector header, which consists of three digits that make up the sector’s three-dimensional address: the using head of this sector(or platter), the track (or cylinder number) and the track position of this sector(ie, sector number). There is one field in the header, in which there is a flag that shows whether the sector can reliably store data or whether a fault has been found and therefore the sector should not be used. Some hard drive controllers will record pointers in the header, and if an error occurs in the original sector, pointers will lead the disk to reserved sectors or tracks. Last, sector header is ended up with a value of Cyclic Redundancy Check(CRC) for the controller to check the readout situation so as to ensure everything is okay.
The second major part of one sector is the segment of stored data, which can be divided into data part and ECC part. During initial preparation, computer will fill this segment with 512 virtual information bytes (the place where actual data is stored) and ECC number corresponding to them.
ECC refers to Error Checking and Correcting, it is a technology which can achieve error checking and correction. ECC value has its own set of calculation formula and algorithm. For Seagate drives, ECC is the common function of Data and LBA, the specific formula is ECC=f (Data, LBA).
Both Data and LBA are input parameters, and this means any change of LBA will result in the change of ECC value. And the reason why UNC error light will be on when sector access interruption happens is just because LBA has changed, and when read & write subsystem using this new LBA to calculate ECC, this calculated ECC value can not match with the stored ECC value. So the read & write subsystem thinks the data of this sector is not credible, and it reports UNC error. But we need to know that not all hard drive manufactures use this ECC formula, such as the ECC formula of Western Digital is ECC=f (Data). We can see LBA is no more an input parameter, and this is the reason why there is no sector access interruption problem among Western Digital drives. In summary, for hard drives which use LBA address as ECC input parameter might have the problem of sector access interruption, like Seagate drives and Hitachi ARM series; for hard drives which do not use LBA address as ECC input parameter wont have sector access interruption problem at all, like Western Digital drives and Toshiba drives.
When referring to LBA change, then we must talk about defect lists. We know that hard disk’ data storage is with high density, so it is inevitable to make some defect sectors during its production process. What’s more, those unstable sectors will gradually aging and will cause data read & write error, then they will turn into defect sectors. These defects and unstable sectors will seriously threaten hard drive’s data security. And in order to protect the data, hard disk manufactures have designed P-list and G-list to deal with those defect sectors, and these two defect lists will be used to record statuses of defect sectors.
P-list is also known as permanent defect list, it is used to record the defects generated during production. After a defect sector is being added to P-list, disk will no longer read or write this sector, but to read and write the next following sector. This operation will change LBA values of all the following sectors, and one sector from reserved area will become LBAmax of the disk.
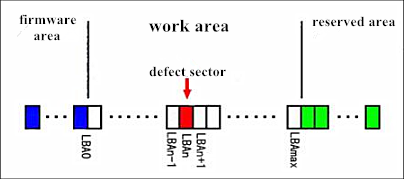
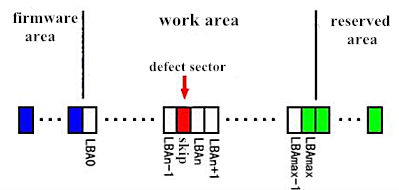
G-list is also known as grown defect list, it is used to record the defects caused by magnetic media die-down during the usage. After a defect sector is being added to G-list, and when disk needs to read or write this defect sector, a sector from reserved area will be relocated and replace that defect sector, so there wont be any influence on other sectors in working area. As shown in the picture:
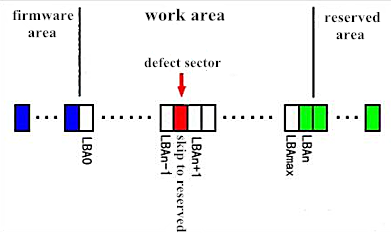
That is to say, if the change of a defect list can lead to the change of LBA value, then ECC value will also be changed, thus resulting in UNC error. This is why when defect list of one Seagate disk is broken will lead to translator disorder, which will result in a situation that scanning can normally read out the data from sector 0 to a specific sector, but from that specific sector to the end, all the sectors are unable to get the data with errors of ERR and UNC.
But we should noted that not all defect lists can lead to the change of LBA value. Only a “dig” list can lead to LBA change, while “replace” list wont affect LBA value at all, this is the example pic of a “dig” list:

This is the example pic of a “replace” list:
Combining with the above two pics and illustrative pics of P-list and G-list, we can find that the so called “dig” list actually means from the next following sector of the “dug” sector, all subsequent sectors will change their LBA value. While “replace” list means an available sector will be used to replace the defect sector, and all subsequent sectors of the defect sector wont change their LBA value.
Comprehensive defect list is a major component of the translator, and the comprehensive defect list contains the following defect lists:
V1: slip list of working area (equivalent to collection of V10 and V40)
V4: alt list (commonly known as A-list, belongs to “replace” list)
V10: P-list (main defect list, actually it is module 03, it is necessary for data recovery, and it can be found in system files and modules)
V40: non-resident G-list
V80: resident G-list
V100: P-list (another display form of V10, effective P-list in translator)
In Seagate drives, both V40 and P-list belong to “dig” list. That is to say, V40 and P-list can lead to “sector access interruption”. And we should know that both adding and missing entries in defect list can result in defect list change. So there are four detailed reasons for Seagate “sector access interruption” problem as we’ve mentioned, four detailed reasons are:
1. Entry missing in V40 (there are lost entries in non-resident G-list)
2. Entry redundant in V40 (there are extra entries in non-resident G-list)
3. Entry missing in V10 (there are lost entries in P-list)
4. Entry redundant in V10 (there are extra entries in P-list)
Summary:
Entry missing and entry redundant in both V40 and V10 will lead to “sector access interruption” in Seagate drives. Common reasons why there are lost entries or extra entries in V40 and V10 can be summarized as the following three:
1. There are errors within interior firmwares
2. Maintenance personnel used wrong parameters to recalculate the translator, resulting in a secondary damage
3. Execute G to P command in a wrong way, thus added entries from G-list to P-list
Generally if it is a first hand disk, then reason 1 owns first priority; if it is a second hand disk, then reason 2 or reason 3 owns more possibilities.
The above all are the contents of analysis on “sector access interruption” of Seagate drives, thanks for your reading.